
Evaluating my app using LLM-as-a-judge
I love to play board games, and I especially love to try lots of new board games - which means I have spent a ton of time reading rulebooks.
A problem that I regularly face is starting to play a new game for the first or second time, and seeing a situation I don’t quite know the ruling on - so let’s pause the game for a second, grab the rulebook, find the section… this rule applies to this, let me flip through to here… wait how does that rule work again - and so on. It can really stop the flow of the game!
So, I thought, how great would it be to be able to search through any rulebook? Or, even better, ask a natural language question and have an LLM figure out the answer based on the rulebook for me? So, I’ve been working on a project to do that called Boardally, which you can check out here.
Now, at this point, there’s nothing fancy about how it works - it’s just a wrapper for Gemini Flash that uploads the game’s rulebook PDF to use as context. My priority for the last few months has been getting the MVP made and working, and improving it later.
Which brings me to the subject of this article - how accurate are LLMs at answering complex board game rules questions?
For the aforementioned priority reasons, until today I hadn’t thoroughly tested how accurate my app actually is!
Why this is an interesting problem
The general problem here is called Multi-Hop Question Answering, or MHQA, which is the task of correctly answering questions when it requires combining multiple bits of information or taking several logical steps. This is of course a popular area of research given LLM’s success at these kinds of tasks, but I don’t think this exact domain (board game rules) has been studied much directly, and I think it’s interesting for a few reasons.
First, as opposed to the typical kind of semi-structured informational text that is broadly used in studying QA systems, rulebooks are highly structured and will often define their own unique terminology for the purposes of describing the game system - terminology that players will often not use when asking a question.
Also, the kind of logic that needs to be applied to answer the questions is a bit different. In a lot of MHQA datasets, the focus is on evaluating the ability of the system to find “bridge entities” to answer questions, like “What is the population of the country that last won the World Cup?”. There’s a direct line of connections between entities that the system needs to establish to answer the question.
In board game questions, though, the answer often lies in evaluating the defeasible logic that rulebooks typically set up - “can I play this card on this target in this phase?” will require looking at several rules and determining what order and what conditions apply - which is difficult for people to do at a board game night, let alone a QA system.
I was able to find a couple works (Structured QA, BoardgameQA) that focus on this, which is going to be really helpful for me as I continue to work on Boardally. Mozilla AI’s Structured QA article in particular is about exactly this topic, and they also collected a test set that includes board game, but also scientific report and technical documentation questions. BoardgameQA focuses on evaluating LMs in defeasible reasoning using a synthetic dataset. I want to focus on real-world board games, and the Structured QA dataset only included questions on 2 games with exact answers, but I want to test implementations that give full natural language responses - so I got to work collecting some test data!
The process
I put together my own tiny test set: 25 question-answer pairs across 5 different board games. These were mostly sourced from actual player questions from Board Game Geek or the subreddits for the board games.
I think this will be a good test set for a couple reasons: Since they’re from real users, they often don’t reference the exact terminology used in the rulebooks, referring to components or phases of the game by whatever word makes sense to them. Also, the questions will naturally tend to be about things that are a bit confusing - they had to ask the question after all!
With this test set in hand, I went about making a minimal testing framework in Python. I decided that since my implementation on Boardally is pretty simple (prompting with full context) I can just reimplement it locally, which also has the advantage of being able to easily test other implementations, LLM providers, contexts, etc.
The LLMs I tested were: Gemini 2.0 and 2.5 Flash, ChatGPT-4o, and Claude Sonnet 4. For each of these, I use 2 implementations: a “zero-shot” implementation where the model is only given the board game name and the question (effectively testing what knowledge about these games they have encoded from training), and a “with rulebook” implementation, where they are provided a PDF file of the game’s rulebook as context.
For each implementation, I run through and give it every question in the test set and record the answers. Then, I use a very simple LLM-as-a-judge implementation with the following prompt to ChatGPT-4o:
You will be given a true answer and a given answer.
Your task is to determine if the given answer is correct or not.
If the given answer logically agrees with and conveys
the same decision as the true answer, then it is correct.
Respond only with a JSON object with the following keys...Then, these grades were saved as the final evaluation result. Each implementation was run on the test set 3 times.
The results
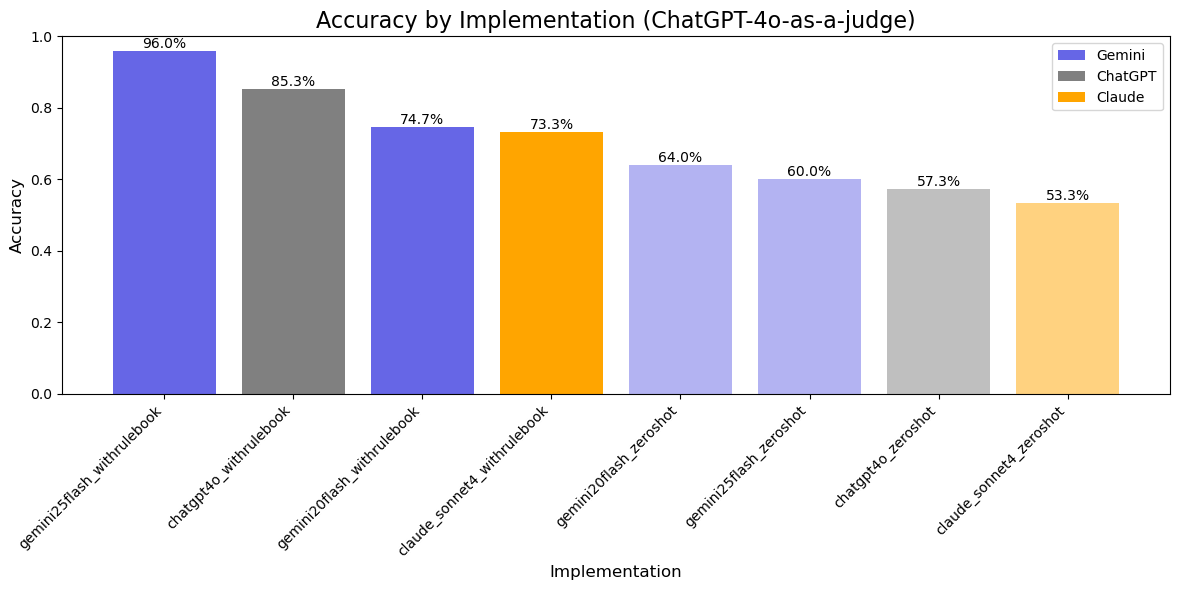
Unsurprisingly, every implementation without the rulebook context (the slightly grayer bars) performed worse.
The overall winner ended up being Gemini 2.5 Flash with 96% accuracy - but there’s a catch!
I added it last minute since I just had 2.0 at first (I’ve been using 2.0 on Boardally since I started it just before 2.5 came out) and was really surprised at how well it performed. That’s when I went back to look at the model info and saw that 2.5 has reasoning on by default - the other ones either don’t have it or default to off.
I didn’t intend to test reasoning models at first, so this was definitely an accident and not a fair comparison. Still, it does show (which isn’t really surprising) that reasoning mode is definitely important for this use case.
Also, there is definitely some error inherent to using LLM-as-a-judge. I didn’t validate every response, but out of the few dozen that I did, I only found a couple that were definitely wrong. That passes my personal margin for error for this quick use case, but I recognize that there’s room for improvement to make a better metric as I move forward.
To me the most useful thing from all this is that I have a testing framework. A big thing I missed out on this run is not saving the token usage - as I iterate and explore different, fancier QA implementations (knowledge graphs?), my goal is to get similar performance with a lower cost. Now that I have this, I can work much faster and immediately see what works without just relying on “feel” from a few manual queries.
Anyways, thanks for reading! If you have questions, suggestions, or just want to reach out, you can find my email on the homepage of this site.